
この記事は、DMMグループ Advent Calendar 2021の1日目の記事です。
こんにちは。DMM.comの石垣雅人(@i35_267)と申します。
普段は、いくつかのプラットフォーム基盤の事業やプロダクトを管轄しながら、エンジニア・デザイナーの組織をマネージしています。
本記事では、タイトルの通り「事業」と「エンジニアリング」について述べていこうと思います。
想定読者は、プロダクトを保有しながら収益出していく事業に関わっているすべての方。
事業責任者やプロダクトマネージャー、将来チームを率いて活動する立場になりそうなエンジニア、デザイナー、プランナーなどの方です。
私はもともとサーバーサイドエンジニアでしたが、ここ数年で事業やプロダクトを作ったり、スケールさせることに責任を負う立場になりました。特にこの1年間という期間の中で、組織を率いて事業を作りながら感じたこと、それに対して行動したことを紹介していきます。そこにエンジニアのこれからのキャリアや技術発展の歴史なども少し加えていきます。
エンジニアが、1行のコードから財務諸表を意識する世界線を目指したい
特に注力したのは、全員が事業に参加することです。エンジニア含めて全員です。
特にエンジニア目線で言えば、至極当然の観点ですが薄れやすい、エンジニアが今が書いている1行のコードあるいは、1つのプルリクエストというミクロな集合体がプロダクトを作り、事業の収支を作っていることを財務諸表レベルで感じてほしいという思いがありました。

課題 / ペイン
事業規模関係なく、組織が大きくなれば、役割や責任箇所の分散によってセクショナリズムが起こりやすい構造になります。サービスをスケールさせていく過程で、組織として密結合だったものが徐々に疎結合になっていきます。例えばエンジニアサイドとビジネスサイドという言葉がありますが、それを役割・権限の最適化といえばそうです。しかし、本来全員が共通して持つべき指針である事業のナラティブから、個々の視座と視野が遠ざかっていくことで、あらゆる事業的な意思決定が自分事ではなくなることを危惧していました。
エンジニアリングの領域に至っては、要求定義で決まっているものを「どう作るか」「作れるか」だけにフォーカスした状態になりやすい。 そうなるとエンジニアは自分が行っている実装がどのように事業に関与しているのかの目的意識がわからなくなり、Howの部分にこだわり出して手段の目的化の出来上がりです。 工数が増えるかどうかばかりを気にしてその機能が競合他社との優位性があるかなどが見えなくなる。 本来のエンジニアリングは競合他社のどこにもない機能優位性をUX/UI/技術を使って凌駕できるかを考える。全く同じような機能を同じ仕様を作ってもつまらないので、スタンダードを踏襲しながらも進化、鮮麗させることを考えるべきで、近視眼的になっていると事業に貢献する技術の主体性も失われていきます。
アプローチ
アプローチとしては、大きく分けて2つ試しました。
- 事業もエンジニアリングも"構造"で捉える。
- スモールチーム(小さい集団 x N)を作り上げ、戦う。
本記事は、その備忘録です。
少々長いので目次で気になる部分だけお読みいただいても構いません。 目次の1, 2, 5は概念的な話で、3, 4, 6, 7は事例を盛り込んでおります。
また、色々なタイミングで「成功事例」といった効果があった取り組みと、まだまだ綺麗事の段階だなぁと、いまだに課題となっている「課題事例」を載せていきます。留意する部分として、具体的な事例はDMM.comとしてではなく弊チームでの取り組みです。
1. 事業のスケールがもたらす、エンジニアリングの犠牲の誤解
まず、話の出発点として、事業拡大のスピードに対するエンジニアリングの犠牲の話をします。 前述したエンジニアの事業に対する主体性の問題は、意識だけの問題ではありません。直接のダメージとしては、明らかに事業のスケールスピードに影響していきます。
エンジニアにとってイメージしやすいのは、事業の急拡大によって満足行くリファクタリングができずにスピードだけを重視した結果、技術負債という名の借金が出来上がり、新規機能追加も保守運用に余計なコストとリードタイムがかかることです。つまり、デッドロック状態です。 負債を貯めすぎると後々巨大なリプレイスが走り、膨大な人件費とその期間中の機能拡充を犠牲にしていきます。
ひとつの論調として、これは単純に「いつ犠牲を払うか」の問題であって事業としてスピードを重視するフェーズもあるので、簡単な話だと「後々、ここはリファクタリングしようね」というのが早々にロードマップに組み込まれており合意されていれば良いという話です。事業的な意思決定とエンジニアリングとの点と点を繋げる作業です。
Is High Quality Software Worth the Cost?
この意思決定もとても大事ですが、ただ、そこまで単純な話ではなく、品質に対するコスト・スピードの考え方は、必ずしもエンジニアリング的にはトレードオフ関係ではありません。 Martin Fowler氏が書いた「Is High Quality Software Worth the Cost?」から引用すると、品質にはexternal quality(ユーザーから見える機能やインターフェイス)と internal quality(アーキテクチャやソースコードなどの内部品質)の2つがあり、ユーザーはプロダクトのexternal qualityにはお金を払って購入するが、 internal qualityにはお金を払いません。
これはユーザーにとっては至極当然です。 機能やUIが優れているAプロダクト(ただし、internal qualityはぐちゃぐちゃ)と機能やUIがぐちゃぐちゃのBプロダクト(ただし internal qualityは綺麗)では、誰しもがAにお金を払うでしょう。

だからといって、internal quality(Exリファクタリング)は二の次で、どんどん機能やUI、UXを最適化していきましょう!では駄目です。 事業戦略を担っているメンバーは中長期的なプロダクト戦略の視点をもっていないければいけません。事業責任者は「スピード重視だから、リファクタリング(internal qualityを整える作業)はあとでしてほしい」ではなく、逆にエンジニアは「いまはスピード重視だから」といって妥協して逃げてはいけません。internal qualityにこだわると、事業の加速に耐えられます。
つまり、今この瞬間はAプロダクトのほうが機能数が多いかもしれませんが、3ヶ月後はBプロダクトのほうが上回っていることを全員が理解しないといけません。
Martin Fowler氏によるとhigt internal quality(内部品質が高い状態を維持)とlow internal quality(内部品質を犠牲)の損益分岐点を比較すると、チームによっては約1ヶ月立たずに開発スピードに影響を与えると言っています。
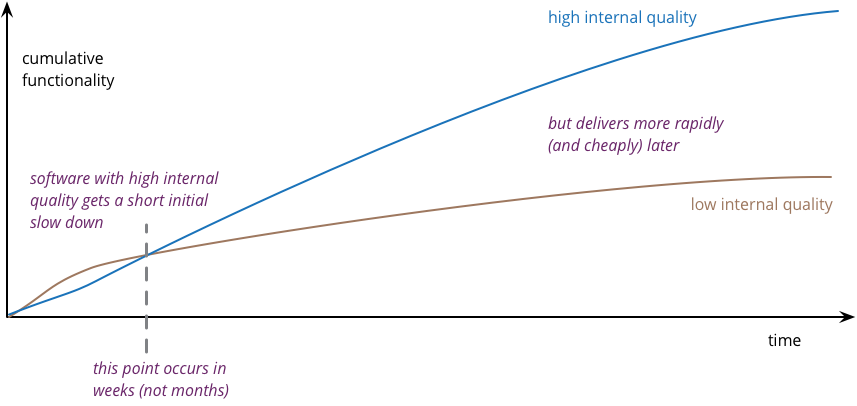 引用 : Is High Quality Software Worth the Cost?
引用 : Is High Quality Software Worth the Cost?
つまり、一瞬は内部品質を犠牲にしてスピードを優先したほうが機能提供スピードは早いのですが、わずか1ヶ月程度で内部品質を高い状態で維持したプロダクトのほうが生産性を上回るということです。 理由としては、高い品質で作った機能を資産として確保できるため、似たような仕組みであればそれをフォークすることで提供スピードが上がっていきます。
内部品質を犠牲にした状態でスピードだけを優先し続けると、悪い品質のソースコード・アーキテクチャにどんどん機能追加していかなければいけないので、イメージに容易く負債が指数関数的に伸びていきます。逆に内部品質を高い状態を保つと良い方向にどんどん伸びていくでしょう。
また、内部品質を高めた状態を続けることによって数年スパンで考えると、前述した巨大なシステムリプレイスもある程度は抑えられるので人件費も抑えられます。その抑えられたコストが新たな機能追加のための人材確保(採用)に予算を回せたり、広告予算に合わせたり、販売価格のプライシングにも影響していきます。

意思決定の合意の質をあげる
紹介した事象はひとつの例ですが、詰まるところ役割関係なく会話のプロトコルを整えながらも全員がこういった事象を理解していると、事業のロードマップとエンジニアリングのロードマップが綺麗に融合できます。 程度はあるにしても、「エンジニアリングが理解できる事業責任者」と「事業の解像度が高いエンジニア」の両方が必要だと感じています。 特に昨今のPdM(Product Manager)や営業やマーケターとエンジニアの間に入るようなPMやディレクターならなおさらです。

まとめ
- 事業のスケールに対して、きちんと技術的な観点も考えないとすぐに競合他社に開発スピードで負けてしまう
- 必ずしもスピードを優先すれば開発が早くなるのかというとそうでもない。external qualityと internal qualityの相関関係を考えないと意味がない
- 結果としては、品質が高いアーキテクチャないしソースコードは、資産となり使いまわしが効いて、指数関数的に提供スピードは上がっていく
参考文献
2. 技術のコモディティー化に多くのエンジニアは敗北する
事業とエンジニアリングの話をする上で、もう少し前段部分を話しておきます。 事業とエンジニアリングを接続する目的の1つとして、技術のコモディティ化のよる、これからのエンジニアの方向性の問題があります。
技術は常に進化し、X as a Service / OSSになる時代へ
今までなかった技術が登場しても、すぐに製品化されます。すると、昔は苦労して皆が実装していたものが平等に利用可能な「武器」となります。 すべてが、X as a Serviceされ、技術の平均化(誰が実装しても大体同じクオリティーが出せる)が行われると、いちエンジニアがもたらすパフォーマンスにも差異がなくなっていくことは想像に容易いでしょう。
もちろん、素早くサービスを立ち上げられる、スケールさせられるテクノロジーの進化なので良い事づくしですが、人という観点では、それらのパッケージ化された技術を使う エンジニアもコモディティ化していくことになります。 こうなると、急に自分事のように感じてきますが、最近では「No Code」も発展し、実際に複雑なコーディングをしなくてもアプリケーションが作成可能になりつつある中で、私たち技術者はその波に押され、エンジニアとしてのスキル「だけ」では淘汰されてしまいます。
エンジニアが進むべき道は大きく分けて、武器を作りコモディティ化を促進する側か、武器を使い倒して事業を作りスケールさせる側かの大きく分けて二択。 しかし、どちらに舵を切るとしても今後必要になるのが、一部の天才を除いては「コードを書く」「サーバーを構築できる」というシンプルな行為だけでは勝てない世界になっていきます。 そういった生存戦略の文脈でも、エンジニアが事業側のことを理解しておくことにメリットはあるのではないかと思います。
少し余談にはなりますが、そもそも歴史をたどれば、技術のコモディティー化を加速させた大きな流れは分けて2つだと思っています。
クラウドとコンテナ技術の発展がコモディティ化を加速させた
1つ目は、2005年ごとに登場した「クラウド」によるコンピューターリソースの可搬性。リソースを所有する時代からボタンひとつであらゆるリソースを利用できる時代になりました。クラウドを利用できるサービスとして代表的なものは、Amazonが提供するAWS。Googleが提供するGCP、Microsoftが提供するAzureが有名でしょうか。 これらのサービスを利用すれば、サービスの多くの部分をパッケージとして利用することが簡単にできるようになりました。
下図のようにインフラ領域で言えばOn-premisesのようにハードウェアからアプリケーションまですべてを自社で所有して管理運用する時代から「任せられる部分は任せる」「自分たちでやるべき部分はやる」という必要な機能を必要な分だけインターネット上から選択できる時代になりました。インフラ領域で言えば、PaaSやIaaSになるでしょう。PaaSまで利用すればサーバーサイド領域をそこまで深く知る必要もなく、アプリケーションのことだけを考えていればある程度のサービスを作れるようになりました。 また、1番馴染みがあるSoftware as a Service(SaaS)というのは言葉の意味でも分かるとおり、ソフトウェアをサービスとして提供されるようになりました。Googleが提供しているサービス(Gmail,etc...)などがイメージしやすいでしょうか。
前述したとおり、エンジニアリングの技術面ではNoCodeツールを筆頭にアプリケーションをインターフェイスをプログラミングする部分でさえ、簡略化して非エンジニアでも作れるようなソリューションも生まれています。

2つ目は、コンテナ技術によるソフトウェアのパッケージ化も大きな進化でしょう。
違うOSごとにアプリケーションを管理する従来のサーバ仮想化技術ではなく、同一のOS上にDockerを代表としたコンテナ管理のソフトウェアを実行することでサーバ上の独立したOSを仮想化して生成します。特に恩恵を受けることになったのは、laC(Infrastructure as Code)と呼ばれるインフラ部分をコード管理技術です。IaCに書かれているソースコードを実行し、イメージを生成するだけで独立したアプリケーションのプロセス実行環境が何度も繰り返し整えられるので、スピーディーでありスケーラビリティにサービスが立ち上げられます。

コンテナ技術はどちらかというと後述するスモールチームでの開発を後押しするのに寄与している部分が大きいですが、 いずれにしても、この2つの大きな技術進化によってチームがプロダクトを作るのに必要な環境・土台のXaaS(X as a Service)利用が進み、技術のポータビリティーが上がったことは間違いないでしょう。
技術そのものではなく、事業課題に「解」を与える事に力点を置く
では、これからのエンジニアはどうなるかを予測していくと、技術の使いこなすことはもちろん、それを使って事業課題に「問い」や「解」を与えることが大きなると感じています。
例えば、技術を使って投資するべきKPIは何か、レコメンドエンジンに対してどういった観点でパーソナライズするべきかといった部分です。 こうした技術そのものではなく、その技術を用いて「何ができるか」「何をするべきか」を考える範囲が今よりも、もっと広くなるでしょう。 詳しくは、このあとのトピックで紹介していきます。
まとめ
- インターネット上で展開されるあらゆる技術は、ソフトウェア化され、簡単に利用できるソリューションになる。つまり、技術のコモディティ化が起こる
- エンジニアリングの領域で言えば、インフラ領域やバックエンド領域もPaaS、IaaSを利用してアプリケーション部分に集中できる時代が来ている
- するとエンジニアのスキル差異がどんどん縮小されていき、エンジニア自身もコモディティ化する
- 一部の天才を除いて、コードを書くだけでは淘汰される時代が来るのではないか
- 技術そのものではなく、事業課題に「解」を与える事に力点を置く
3.事業とエンジニアリングを接続する
さて、少し前段が長くなりましたが、具体的にこの1年間で事業とエンジニアリングをどう繋いでシームレスな事業の開発環境を作ってきたかの話に移ります。
事業もエンジニアリングも、構造で捉えて思考する。
昨今、DX(デジタルトランスフォーメーション)という言葉をよく聞く様になって久しいですが、いわゆるITが浸透していない領域においてデジタルの観点を入れることで良い変化が起きるという仮説です。 エンジニアという職種柄、元からゴリゴリにデジタルを扱っている仕事をしているとそこまで深く自分事になりませんが、少し昔を遡ると2011年にMarc Andreessen氏が言及した「Why Software Is Eating The World」のほうが馴染みがあるかもしれません。

引用 : https://future.a16z.com/software-is-eating-the-world
DXというのは、非デジタルの部分をデジタル化にするということだと思いますが、1番のデジタル化の効用は「データ」として出力されることだと個人的には思っています。
事業とエンジニアリングを繋ぐという文脈も、少し規模がミクロに感じますが、これに近くて事業を作っていくプロセスをすべて「データ」でプロットしていくことで、事業=サービスの振る舞いがデータとして記録され、ログデータとして出力されると、一気にエンジニアリングが事業に影響する度合いが高まり、接続されていきます。
振る舞いがデータとして見れるようになると、人間では人力でやるには到底難しい行動(分析やレコメンデーション)をエンジニアリングによって自動化できるようになります。
特にレコメンデーションについて、その権化と言っていいのはNetflixでしょう。
詳しくは、以下記事に譲りますがユーザーの行動ログをほぼリアルタイムで追いながら、スクロールするためにタイトルをレコメンデーションしていったり、同じ作品でもユーザーによってサムネイルを変えたりしているのは有名でしょう。現在も様々なアプローチをしながらパーソナライズされています。

引用 : https://speakerdeck.com/i35_267/765dd721-09f9-4c71-8b4e-0b8a9d325181
netflixtechblog.com netflixtechblog.com
事業をナラティブ(物語)を「データ」を使って読む
データ(詳細にはログデータ)で出力されると、事業のナラティブ(物語)が見えてきます。ユーザーの行動が見えてきます。
このユーザーは、28歳の女性で、DMM.comにはGoogle検索で流入してきて動画のコンテンツを200円クーポンを使って800円で購入した。という行動ログがわかるようになります。 これはトラッキングを細かくすればするほどログデータとしてDWH(データウェアハウス)に蓄積されていくので、もっと細かく観測することができます。

引用 : DMM.comを支えるデータ駆動戦略 | 石垣 雅人, 松本 勇気 |本 | 通販 | Amazon
事業改善の繰り返しは、こうしたログデータをもとに活動していきます。
KPIで事業を語る。共通言語としてのKPIツリー
私たちは、立場・役割・職種が違えど、最終的には事業をスケールさせることに責務を持っています。不確実性の中で、事業が死んでしまえば、そこにあるシステムもなくなります。それはとても悲しいことです。
組織全体で、「データ」を使いながら事業改善を進めていくにはユビキタス言語のような共通言語を持つ必要があると感じます。 それで使っているのが、KPIです。 KPIとは、重要業績評価指標(Key Performance Indicator)の略で、事業におけるKGI(Key Goal Indicator)といった最終的に達成したいゴールに対して、どのような要因プロセスを経て目標を達成するかを数値で表したものです。 また、KPIを設定するにあたってはKGI(Key Goal Indicator)の理解やKGIの要因を分解したCSF(Critical Success Factor)に関する知識が必要となります。 構造としては次図のような形になります。

KGIが事業における中長期的な目標であるのに対して、CSFとはKGIを達成するために必要な要因です。 例えば、売上を1億円にするといったKGIの目標があったときに、それを達成するためには1日のサイト訪問者数をどれだけ伸ばす必要があるのか、それとも1ユーザーあたりの平均購入額を上げる必要があるのか、などいくつかの要因が考えられます。このようなKGIに繋がる指標がCSFと呼ばれるものです。そして、KPIとはこのCSFを具体的な数値にした目標のことです。 例えば、売上を1億円以上にするためには、CSFである訪問者数が10万人必要だとしたら、その定量的な数値こそがKPIになります。平均購入額を1,000円にしたいといった目標があれば、それもKPIとなります。
最近では、ほとんど何をするにもKPIをもとに会話することが多くなりました。 事業の戦略を話すときも、課題を話すときも、施策を実施するときも、ほとんどが対象KPIをどのぐらい上げたいかで会話をして、また主観で会話するのではなく、実際のKPI数値のファクトをもとに会話するようになりました。 ファクト(データ)の意識を全員が持つ努力をしました。 もちろん、そのデータはチーム全員が見れるようにダッシュボード(弊社でいうとre:dash)を使ってモニタリングしています。

「成功事例」効果ありだった取り組み事例
以下が、実際のチームでのデータ文化を根付かせるために行った組織施策です。
- KPIダッシュボード = 1つのプロダクトとしての意識性をもたせる。
- バージョン管理もする(クエリレビュー等)。
- 毎日のデイリースクラムでKPIダッシュボードを必ず確認する。
- 健康診断ダッシュボードを作成して、1分以内にチェックするべきデータを確認できる状態へ。KPIモニタリングの基礎。データを見る文化を形骸化させない。
- 毎週1hデータ分科会を開催して、予実比の確認 / 今週作ったデータ(クエリ)の確認 / 各施策を進捗確認を全員で行う。

よくあるのは、「数値が大事だ!」といいつつも、どうしても数値を見る人が限定的になったり、KPIダッシュボードを作って終わりになり、運用が形骸化するケースが大きく見られました。 それを防ぐために、意思決定の会話プロトコルをKPIにしたり、構造的にKPIダッシュボードを見ていないと会話についていけない環境作りをしました。
「課題事例」綺麗事の段階
とはいえ、課題もありました。 特に多いのは、クエリのレビューとそこから来るデータの妥当性です。 皆が欲しい情報を自分でクエリを書いて可視化するのはとても良い傾向だったのですが、データを整合性を取るためにコードレビューのようにクエリレビューをします。この負荷がとてつもなく高くなります。
エンジニアは、ソフトウェア開発がメインなので、そういった意味でのコードレビューは慣れているのですが、まだまだデータを見る力自体が全員均等にスキルレベルが統一されていなかったり、そもそも何を証明したいクエリなのかを施策担当者ではないとキャッチアップが厳しいといった課題があります。ランダムでのレビュアー選定だと偏りと負荷があがり、プロダクト自体の生産性にも影響を与えていました。
いまも、試行錯誤中ですが一旦は、そのクエリを必要としている領域の担当者(施策担当者など)の間でレビューしたり、事業責任者のレビューでOKなどの運用を試しています。 
参考文献
4. 正しい戦術を"仮説"と"実験"で探っていく
何をするにも、すべては仮説ではありますが、事業の目指すべき方向をKPIのキードライバーで定められたら、あとは仮説検証をぐるぐる回します。 少し全体像を話すと、「KPIによって正しい方向を定めて、正しい戦術と、正しいリソースで攻めて行く」のがプロダクト開発だと思っています。
特にエンドユーザーが近くにいるようなビジネスモデルだと、正しい戦術をもとに”実験”がどのぐらいできるかが肝になっていきます。 実験というのは、実際の経験なので、実際のユーザーに適応しながら、規模によってはA/Bテストを実施して行きます。
 引用 : https://speakerdeck.com/i35_267/765dd721-09f9-4c71-8b4e-0b8a9d325181
引用 : https://speakerdeck.com/i35_267/765dd721-09f9-4c71-8b4e-0b8a9d325181
ここでいう"戦術"というのは、いわゆる施策のことです。 例えば、新規ユーザー数のKPIを伸ばしたいときに、大きな機能追加が良いのか、UI刷新なのか、キャンペーンなのか。キャンペーンならどんな方式だったら沢山のユーザーが参加してくれるのかといったマーケティングな側面もあるでしょう。

過去施策 x データ分析から、施策Aは+2.0%程度増加が見られそう、施策Bは+〇〇%、施策nは、と予測はできますが、やはり仮説です。 実際に試していき、実測値を貯めていきながらアジャイルマーケティングをしていきます。
問いたい “ 仮説 ” と それを証明する “ 実験 “
仮説を証明するために、どういった戦術(施策)を組んで実行するかを考える際の大前提は「問いたい仮説に対して、その戦術(施策)で、果たしてきちんと証明できるか」です。
よくある失敗パターンとしては、世の中にある施策を何も考えずに踏襲(TTPS)してやってしまうパターンです。 正しく課題となるKPIを考えて、それに対する施策を実行する必要があります。
例えば、よく「友だち紹介キャンペーン」と題して新規入会するとポイントが貰えるという、ほぼスタンダードになっている施策があります。 その場合に、単純に「新規入会を増やしたほうがよい!」ではなく、予算も考慮しながら、きちんと今のプロダクトは新規入会数のKPIを増やすのにフォーカスするべきなのかきちんと考えていきます。そもそも新規流入が入ってきてもバケツの穴の状態でリテンションがまったくされてないサービスであれば、コストを払って新規入会を増やしてもどんどん抜けてしまいます(フェーズによってはそれでも良いことはあります)。 それよりも、今は熱狂的なコアユーザー(7 days Retentionが高い等)を作るための実験が必要なフェーズかもしれません。
下図の例も同じで「支払手段を変更してほしい」という明確なKPIがあったときに、単発で変更してもらうのではなく継続的に支払手段を変えたほうが継続的なメリットが高いという"仮説"があったとします。 これはひとつの例(仮説)ですが、そのときに一過性の「今日だけ!最大ポイントが〇〇pt当たる!」という施策では、その日だけで支払手段を変更してくれたとしてもその日が終われば戻ってしまう可能性が高いと推察して(これも実験でわかることではあります)、「支払手段乗り換えで、毎回〇〇%ポイント還元!」のほうが、もしかしたら「継続的に移行してくれるかもしれない」と考えます。
 引用 : https://speakerdeck.com/i35_267/765dd721-09f9-4c71-8b4e-0b8a9d325181
引用 : https://speakerdeck.com/i35_267/765dd721-09f9-4c71-8b4e-0b8a9d325181
BMLループで、仮説検証プロセスを作っていく
実際の実験プロセスですが、これはよくあるリーンスタートアップの手法ですが、採用しています。

BMLループの構成要素は、大きく分けて3つあります。
- Build …… つくる
- Measure …… 測る
- Learn …… 学ぶ
プロセスの流れは次のとおりです。BMLループの仮説検証サイクルはBuild→Measure→Learnというステップを踏みます。まず、Buildは実際にプロダクトをつくるフェーズです。次が、プロダクトをユーザーに届けたあとの計測(Measure)のフェーズ。最後に、そこから学習するフェーズ(Learn)の3つとなります。 これをいかに高速に回していけるかが重要となります。
Build→Measure→Learnの間を埋める形でIdea、Product、Dataという3つの状態が保管されています。流れをまとめるとこのような形です。
- Learn → Idea = 仮説を考える
- Build → Product = どう作るか
- Product → Measure = 計測する
- Measure → Data = 計測してデータをつくる
- Data → Learn = データから何を学ぶか
このBMLループの出発点を考えるとIdea→Buildだと思うかもしれませんが、仮説を立てていくというのは何かしらの学習をもとに立案しなければ、ただの思いつきや経験則といった仮説の妥当性が 担保できていない状態になるので、まずはLearnから始まります。
また、実際には逆回転からの順回転です。 その仮説で証明したいことを確認(先に数値管理ダッシュボードを作成する)してから、施策をBuildしていく流れになります。
「課題事例」綺麗事の段階
ここに関しての取り組みについては、先に課題から行くと、BMLループあるあるの課題にそのままぶち当たりました。 主に2つです。
仮説検証からの学習の部分が全然できていない
これは、仮説もあって施策をみんなで決めて、実施したは良いが「成功 / 失敗」の判断ぐらいはするが、学習して次の施策に活かさないことが初期では多かったです。 いわゆるどんどんアイディアは思いつくので、これが駄目だったら次!みたいな形になっていて施策の成功率も低くなりました。
- 仮説 → 施策 → 実施→結果→理解(認識)→次へ
- 仮説 → 施策 → 実施→結果→理解(認識)→ 学習→ 次へ
ログが仕込まれてない → 検証 & 学習ができない
これも、あるあるですね。先に「何を証明したいのか」を決めてから施策を実装しないと必ずトラッキング不足での手戻りが発生します。 実装までにトラッキングの設計が不十分というケースが多くありました。
「成功事例」効果ありだった取り組み事例
課題事例をもとにした改善案として、よかった取り組みとしては、逆回転からの順回転はうまくハマりました。 つまり、仮説を先に決めた上で先にダッシュボードを作成してしまいます。そうすることで、「どんな仮説で」「何を証明したいのか」をきちんとチーム内で認識が取れた上でユーザーに適応できます。

まとめ
- 事業とエンジニアリングは、KPIを共通言語にして語る。
- そうするとエンジニアリングと事業の距離が縮まり、影響度合いが密接になる。(DXの文脈)
- 正しい戦術(施策)は、仮説と実験によって探っていく。
- BMLループは、速さだけではなく「何を証明したいのか」をきちんと合意を取ってから進めたほうが手戻りがない。
参考文献
5. スモールチーム(小さい集団 x n)と技術を接続する
ここから、少し組織論の話に入ります。
事業とエンジニアリングを繋いだ上で、その中でどういったチーム構造、運営で戦っていくかです。 着眼点としては、昨今の開発現場では当たり前になった「小さいチーム」での開発について、スモールチームと名付けて、その歴史と起源を振り返るとともに、実例に落とし込んで行きます。
スモールチームと技術の力学を徹底的に理解する。
近年のプロダクト開発では当たり前となった「スモールチーム(小さい集団)」での開発について、あらゆる側面から分析していきます。スモールチームが前提になった背景には、アジャイル型の開発、クラウドを中心としたあらゆる技術進化が影響しています。それによって、チームの形状や計測性、仮説検証のやり方までもが変化し続けています。
近年の技術進化は、システムの形だけではなくチームの形も変えてきました。 大きなムーブメントの1つが、表題にもある「スモールチーム」です。 最近は多くの現場で、スモールチーム(少人数)をベースとしてプロダクト開発を進めている様子を目撃するようになりました。 その背景には、アジャイルの登場から、クラウド、マイクロサービス、CI/CDの進化を中心とした「技術」の発展があります。 これらの概念 x 技術がもたらしたものは「チームの独立性」の向上です。 ひとつのチームで行う活動のバッチサイズ(処理量)がどんどん小さくなり、疎結合の集団体(チーム)が増えています。その点と点がスモールチームと技術のエコシステムによって掛け合わせられうようになりました。また、その功績の1つとしてその活動のほとんどが計測可能にもなりました。
一方、実際の現場に目を向けると、なんとなくの責務でプロダクトや機能を分解して、そこにチームを割り当て、アジャイルっぽくイテレーションを1、2週間で区切って開発を進めているチームは多いのではないでしょうか。
なぜ、スモールチームが良いのか。どの粒度でチームを分割し、構造を変えるべきかに悩んでいる方も少なくはないと思います。そうした課題感をお持ちの方を対象に、これまでどういった技術の発展からのスモールチームでのプロダクト開発を可能にしてきたのかの片鱗をご紹介できればと思います。 スモールチームは、技術進化とともに日々のその形をアップデートいきます。
プロダクトを作る術(技術)とプロダクトを作る人(組織)
では、まず「なぜ、スモールチームの話をしているか」を見ていきましょう。 プロダクト開発におけるプロダクトマネジメントの基本は、「何を作るか」それを「なぜ作るのか」を考えることです。 その2つに対して、正しい戦略で、正しい戦術をもとに、正しいリソースを使って、多くは限りある予算の中で「ヒト・モノ・カネ」を使い、3つの正しさを動かしていきます。 この中で、1番難しくもありながら、レバレッジが1番聞くのが「正しいリソース」の部分です。つまり、人。その人が作り上げるのがシステム = プロダクトです。
プロダクトマネージャーが、まず考えることの多くは、どうやってコスト(イニシャル、ランニング)を抑えながらも、良いプロダクトを継続的にユーザーに届けるかでしょう。 よりコストを抑えながら、ROI(投資対効果)が高く、レジリエンスが効いたプロダクトが作れることに越したことはありません。
ただし、言うは易しです。とても難しいことです。 少数精鋭という言葉がありますが、そこまで都合よくスーパーヒーローが採用できるわけはなく、いまの組織にいる人の力量が、現組織のケイパビリティの限界。つまりプロダクトの限界です。
ただ、できることはあります。 それは、組織の構造やプロセス、技術の相関性をマージしながら歯車を回すことです。 プロダクトを作る術(技術)とプロダクトを作る人(組織)の歯車が噛み合っていない状態では、スピード感を持ってプロダクトは前には進みません。
すべては「スモールチーム」を前提とした技術進化へ
具体的に議論に進みます。 まずは、技術進化がスモールチームに対して、どう関係してくるかを考えていきましょう。
スモールチーム = アジャイル型?
さて、スモールチームでのプロダクト開発は、最近でてきた概念ではありません。 よく目につくようになったのはアジャイル開発宣言が出てきた浸透してきた2000年代初頭でしょうか。 それまで主流であったウォーターフォール開発のように、1つのインクリメント(成果物)を作るにあたって、まずは全体を計画するところから始まり、要件定義フェーズ、開発、テストといった工程をベルトコンベアのように作り込む。各フェーズのロールバックは基本しないという「計画主義的」な開発手法から、こまめに計画の地図を広げ、向かうべき方向を時間軸をベースに確認しながら、できるだけ不確実性を小さくして進む。その活動の中で実際に手を動かし、PoC(実証実験)やMVP(仮説検証可能なプロダクト)を通して動くソフトウェアを作る。チームは計画のズレを軌道修正するではなく、ユーザーからのフィードバックをもとにプロダクトを軌道修正をするアジャイル開発に変わってきました。
ケーキ作りで、イメージしてみます。例えば、いちごのホールケーキを作るのにあたって、生地を作るチームと上のトッピングを作るチームは別で、それぞれの工程に積極的に関与しないのがウォーターフォール型の開発です。完成形がイメージできるのは最後の接合部分で、ここで成果物が違えば、手戻りリードタイムが大きいでしょう。また、実際に出荷し販売したとして、ユーザーの反応がいまいちでも「いちごのホールケーキ」という成果物は崩せず、売れない場合は廃棄しかありません。 一方、アジャイル型の開発というのは、ホールケーキを1番はじめに作るのではなく、ショートケーキを作ります。できるだけバッチサイズを小さくしてユーザーに提供、駄目だったらトッピングを変えたりしながら軌道修正していきます。

もちろん、両者の対比構造として、それぞれのPros / Consはあります。
一概にアジャイル型が良いわけではなく、プロジェクトの種類(=何を達成したいか)によってはアジャイルよりもウォーターフォール型のほうが圧倒的にリソースがスケールしやすかったり、予算計画が立てやすい点があります。 逆にアジャイル開発は、小さく作ってユーザーにフィードバックによって柔軟に変えていくことを希望しますが、簡単なことではありません。特に開発においては先を見越した状態で不可逆性が高いもの、例えばデータスキーマなどは、結局先に設計が必要など考慮する点は沢山あります。ショートケーキサイズで、すべてが開発可能ではないのです。
Swarming〜群れながら、突き進む〜
スモールチーム(小さい集団)を沢山作る組織運営的なメリットは、"Swarming"にあります。 Swarmingとは、何かの目的に対して、群れながら突き進んでいく様子です。
よくアジャイルの文脈で使われるものですが、強い群れは、暗黙知を共有しながら細かく指示系統をしなくても戦える組織です。その場合、数が多すぎても統制が難しいですし、少なすぎても心許ありません。 詳しくは以下のスライドに譲りますが、アジリティーをもとめるプロダクト開発の現場では数と役割、暗黙知を意識しながら一定数の人数でのスモールチームで戦うことが良いと考えています。

チームサイズのスパン・オブ・コントロール
主にエンドユーザー向けのサービス開発現場において主流となったアジャイル開発は、できる限りプロダクトチームにオーナーシップを持たせます。オーナーシップとは、権限と裁量、責任、自律性です。理由としては、独立したプロセスで意思決定を早めながらプロダクト開発の不確実性に対応できるようにするためです。
また、チームサイズにも注目すると、Amazonが提唱している「ピザ2枚ルール」や、イギリスの人類学者であるロビン・ダンバーによる「ダンバー数」あたりが、チームサイズの概念が有名でしょうか。
- 「ピザ2枚ルール」・・・効率とスケーラビリティの観点で、社内のすべてのチームは2枚のピザを食べるのにピッタリな人数でなければいけない。
- 「ダンバー数」・・・人類学的に3~5人「社会集団(クリーク)」が最も親密な友人関係を築ける人数である。

こうしたスパン・オブ・コントロール(Span of Control)= 管理できる限界統制範囲、つまりコントロールできる範囲はあらゆる要因によって左右されますが、1チームの人数としては5~10名の範囲が推奨されています。 当然、私たちの世界でいうプロダクトを開発するチームも、もれなく1つのチーム人数には限界があるということになります。これを無視して大人数を1チームにするとチームという集合体が機能しなくなります。つまり、チームにオーナーシップをもたせながらも、チームサイズをコントロールする「スモールチーム」での開発が基本原則となってきます。
とはいえ、たとえチームサイズを最適解で分割していても、扱っているプロダクト、システムも同じように分解されていないと意味がないのは当然イメージしやすいでしょう。 オーナーシップをもったチームが独立したプロセスが作れず、他集合体(チーム)と密結合でプロダクトを作っていく光景はよく見ますが、これではスモールチームでの効用が少なく恩恵も受けられません。どんどんチームだけがサイロ化していき、「あのチームは何をしているのかわからない」「勝手なことをして障害を起こし、それが自分の担当プロダクトにも影響している」といった悪循環が生まれてきます。 ここをうまく、後押ししたのがソフトウェアアーキテクチャの進化です。
昨今のソフトウェアアーキテクチャの進化は、上記の課題感の解決方法とかなり合致した進化を遂げています。 ここについては、前述したクラウドやコンテナ技術の発展の影響が大きいです。
特質するべきは、こうした技術進化によって同時に技術がコモディティ化することは言及しましたが、悪い意味で捉えれば、誰が実装しても"だいたい"同じような高品質でサービス提供が可能になり、エンジニアのスキル自身もコモディティ化するようになったとも言えますし、良い文脈で言えばコンピューターリソースを少人数でもサービス規模関係なくマネージドサービスで管理できるようになったため、以前のように多くのエンジニアを投入してスケールさせなくてもよく、サービスが提供できるようになったとも言えます。
現に有名な事例としては、Instagramの開発体制があります。 プロダクトローンチから、わずか9ヶ月でFacebookに10億ドルで買収された話は有名ですが、驚くべきは社員が13人であったこと。かつ当時のユーザー数は、既に3,000万人いたことから、数名のエンジニアチームでその規模のトラフィクを捌いていたことになります。 それを成せたのも、スモールチーム x 技術の部分でのスケーラビリティを支える融合があってこそだったでしょう。
プロダクト開発が、1つのチームで完結するようになった技術的背景
そうした技術の登場と合わせて、システムと組織形状の考え方も発展しました。
「DevOps」や「マイクロサービス」という考え方です。それに付随する形で「コンウェイの法則」という原理原則についても言及されるようになりました。 どれもが、今では標準的に使われれる技術や考え方になってきていますが、ここでひとつ共通しているポイントは、どれもが「チームの独立性」を支える技術、考え方となっている点です。逆を返せば、スモールチームで開発するときにこれらの技術を利用せずにプロダクトを作ることは現実的ではないでしょう。システムやその周辺技術とチームの形・組織パターンというものは常に対になって考えなければなりません。
セクショナリズムとDevOps
2009年初頭に出てきたDevOpsという考え方は、それまでによくある形式としては開発チーム(Development)と運用チーム(Operations)に分かれていた開発体制をお互いが協調してプロダクトを作っていこうという考え方を示したものです。
時代として、アジャイルが浸透し始めたことによって、頻繁にデリバリーしながら不確実性に対応しなければいけませんでした。いかに柔軟にユーザーのフィードバックを受けながら、プロダクトをアップデートしていくかを重要視している中、「新規追加」をスピード感保ちながら沢山したい開発チームと、「安定稼働」を損なわれるのではないかという運用チームの多くは、少なくともセクショナリズムであり、対立的な構造にありました。
そんな背景の中、DevOpsの原典ともいえる、2009年にO’Reilly主催の「Velocity 2009」というイベントにおいて、John Allspaw氏とPaul Hammond氏による「10+ Deploys Per Day: Dev and Ops Cooperation at Flickr(1日に10回以上のデプロイ: Flickrにおける開発と運用の協力)」というタイトルのプレゼンテーションがありました。
この中では、自動化の重要性やFeature flagsによる機能のon/offの実現、laCによるインフラのコード管理、バージョン管理、ChatBotといったチャットツール経由からワンステップでビルドやデプロイができるべきといった、2021年現在では当たり前にりつつプラクティスが述べられています。

引用 : https://www.slideshare.net/jallspaw/10-deploys-per-day-dev-and-ops-cooperation-at-flickr
こうした背景から、「DevOpsエンジニア」と呼ばれる"できるだけ運用を自動化して柔軟に継続的デリバリーできる自動化環境を整えそう"という動きをするエンジニアも増えました。
NoOps -> SRE
DevOpsが注目を浴び始めた頃、2011年にForresterがひとつのレポートを出しました。「Augment DevOps With NoOps」と呼ばれるもので、ここにはクラウドサービスの進歩により、あらゆるプロセスが自動化されることで運用や運用チームそのものがいらなくなる。つまり、「NoOpsである」 ということが書かれています。あわせて、DevOpsを推し進めていたNetflixのAdrian Cockcroft氏が書いた「Ops, DevOps and PaaS (NoOps) at Netflix」も読むとよく理解できます。 その書きっぷりから拡大解釈されることが多かったですが、言いたいことはプロダクトを運用・保守するにあたって、運用チーム(Operations)は人数によってスケールするのではなく、自動化ツールの提供によるスケールを目指すべきだということです。運用するサービスが増えたら、それを運用する開発者をチームに招き入れるのではなく、自動化ツールを作る開発者を増やします。
ひとつ誤解しがちなのは、運用チームが要らなくなったのではありません。運用チームの役割が変わったという言い方のほうが正しいでしょう。これが今でいうGoogleが提唱している「SRE」という形に近いでしょう。 一連のバリューストリームに対して、ウォーターフォール型の開発のように開発は開発チーム、デリバリーは運用チームという工程で分かれていたものが、運用チームはツールを開発し提供することで、直接プロセスには介入せずに運用チームが開発したツールを利用してもらうという形になりました。これによってリードタイムが短くなっただけではなく、運用チームはプロダクトを多くなっても、それごとに運用チームを立ててプロダクトごとに配置する必要はなく、ツールを提供すれば良いためスケーラビリティがとても向上しました。つまり、運用チームもスモールチームで成り立つようになりました。
合わせて開発チームに対して、ツールを提供することで開発チームが作って終わりではなく、好きなときに好きな機能を好きな量リリースできるようになり、開発から運用保守まで行う時代になりました。

マイクロサービスとコンウェイの法則が、スモールチームとシステムの在り方を定義した。
さて、DevOpsやSREといった考え方によって、1つのチームでプロダクトの開発からデリバリーが完結するようになり、マネージドサービスに任せられる部分は任せることで、サービス規模を人力でスケールさせる必要が少なくなったので、スモールチームで大規模なサービスに太刀打ちできるようにもなりました。
次に着目するのはマイクロサービスという考え方です。 昨今のプロダクト開発におけるソフトウェアアーキテクチャの考え方としては、デファクトスタンダードの考え方になっているでしょう。 マイクロサービスの考え方は、アジャイル的な組織形状・パターンの考え方と、DevOps的なシステムプロセスの考え方がうまく融合した考え方です。 この2つがなければ、成り立たなかった考え方だとも言えます。
マイクロサービスという考え方を広めたのは、James Lewisと2001年のアジャイルソフトウェア開発宣言を策定した1人でもあるMartin Fowlerが書いた「Microservices - a definition of this new architectural term」という記事でしょう。
マイクロサービスの理解の第一歩としては、モノリシックな環境 = 単一のユニットとして構築されたモノリシックなアプリケーション を対比にかけて考えるとわかりやすいです。単一アプリケーションを小さいサービスの単位で、独自のプロセス(多くはAPI(アプリケーションプログラミングインターフェイス))で通信し、ビジネスのドメイン単位で分割し互いの依存関係が少なく独立して開発を遂行できるソフトウェアアーキテクチャの形を"Microservices"と名付けました。
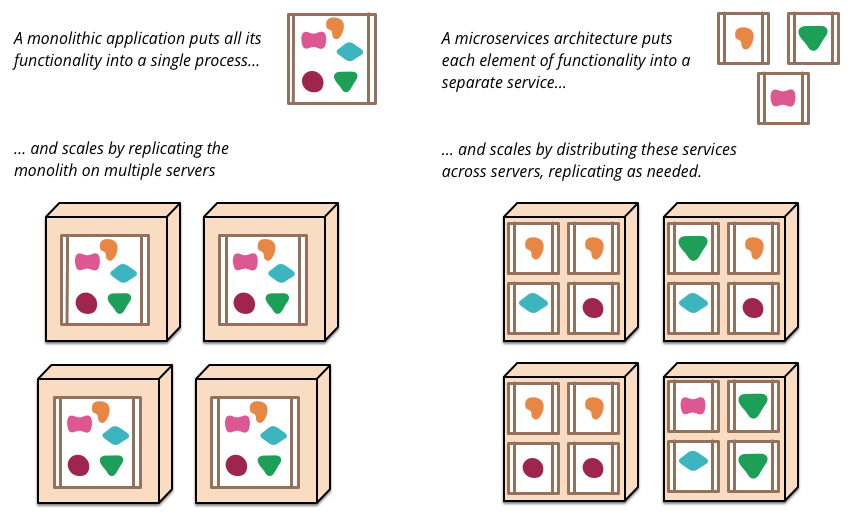
引用 : https://martinfowler.com/articles/microservices.html
このマイクロサービスを後押ししたものとしてはやはりクラウド、アジャイルの発展があります。 アジャイルチームで独立したプロセス環境下の中で、開発を推し進めようにもモノリシックな環境では複数のアプリケーションが同一のサーバー側アプリケーションに存在するため、徐々に機能数が増えたり技術的負債が蓄積することで、「組織構造」起因での変更可能性のハードルが高くなります。 つまり、モノリシックな環境では、アジャイルなスモールチームでの高いリリースサイクルにシステムが耐えられなくなります。そんな中、うまくクラウドサービスが発展してコンテナ技術とXaaSを利用しながら、環境を分離できるようになりました。
また、クラウドサービスの部分でも言及しましたが、サーバーコストが抑えられることもマイクロサービスを後押しする形となりました。 実際にモノリスな環境から、ビジネス機能単位でマイクロサービスに移行する際の懸念のひとつとしてサーバーコストがあります。単純に分割した分だけサーバーを分ける必要があるからです。一方、コンピューターリソースを所有から従量課金になったことでリソースがControllableになり、アプリケーションやデータベースを細かく分割してもトラフィック規模なデータサイズ、レコード量によって柔軟にコスト分割させることができようになったことも影響していると考えています。
コンウェイの法則と逆コンウェイの法則
マイクロサービスと相関してよく語られるものに「コンウェイの法則」という着眼点があります。 マイクロサービスというのは、あくまでもソフトウェアアーキテクチャだけの考え方ではなくて、アプリケーションを分割した先には、それを作っているチームがいます。独立したプロセスを活かす意味でも分割された1つ1つのコンポーネント単位でオーナーシップを持ったスモールチームがいるといっても良いでしょう。
コンウェイの法則とは、組織の集合体とアーキテクチャの相関関係の現象を表したものです。 メルヴィン・コンウェイが提唱した概念で、一言で言えば、以下の表現で言語化できます。
「システム設計(アーキテクチャ)は、組織構造を反映させたものになる」と述べています。
つまり、システムの形とそれを作っている組織の形は同じになるということです。大きいモノリスなアプリケーションがあれば、同じく大きい開発チームがあり、逆に小さいアプリケーションが沢山あれば、小さいチームが沢山存在する傾向があるということです。 逆を返せば「悪い組織構造はそのまま悪いシステムを作り出す」ということも言えます。 組織構造が先か、システムが先かは「鶏が先か、卵が先か」問題と同じですが、どちらにしてもお互いが相関しあっていることは間違いありません。

また、これを逆手にとって、組織の形状を設計するときに理想のシステムアーキテクチャを描き、最初からそれに合わせた組織の形状をグランドデザインしてしまおうという考え方が逆コンウェイの法則です。たとえば、マイクロサービス化を進めるのであれば先にドメイン境界をもとに「どういった単位で分割するか」を決め、そこにチーム編成をあわせていく。そうすると自ずとマイクロサービスの因子に対してスモールチームが複数ある状態になるでしょう。 もちろん、理想論であり、実際には既存のシステムがあり、そこには既に人がいるため、綺麗な分割に対する人材配置にはならないことが多いですが、理想の考え方としては理解できます。
以上、スモールチームと技術の力学の話でした。
まとめ
- チームの最適なサイズとしては、スパン・オブ・コントロールの文脈で「ピザ2枚ルール」や「ダンバー数」から5~10名程度
- チームの形状・構造と技術は相関させながら、アップデートさせていく必要がある。
- クラウド、コンテナ技術によって、チームの独立性を担保する動きができるようになった。
- DevOps、NoOpsの考え方によって、プロダクト開発が1チームで完結できるように土台が揃った。
- そこから、マイクロサービスという考え方が出てきたことによって、スモールチーム x アジャイルでの開発が基本になった。
参考文献
6. 正しいリソースをどこに / どのぐらい突っ込むか問題
スモールチームでの開発が実現可能になった歴史を見てきましたが、では実際にどういったサイクルで開発をしていっているか見ていきましょう。 フレームワークとしては、前述したBMLループになりますが、もう少し具体的に定義すると下図です。
少し、おさらいにはなりますが、KPIによる課題となる数値の抽出と目標値の策定。それをスクラム開発であればスプリントバックログへ落とし込み、チーム生産性のスループットを意識して優先度順に施策をBMLループを基準にビルドしていきます。 ユーザーからのフィードバックは、ログデータとして計測されていくので学習しながら次の施策もアップデートしていきます。

ここで課題感としては、バッチサイズを意識しながら、どこに / どのぐらいのリソースを / どの期間突っ込むかのコントロールです。 一定の選択と集中は必要ですが、プロダクトは常に動き続けていますし、人も変化しつづけます(減ったり、増えたり、育成したり)。 すべてを器用にこなしながら走るしかなく、施策も、リファクタリングも、データ分析も、UX改善も、個々の目標も同時に考えてやっていきます。

「成功事例」効果ありだった取り組み事例
ここはまだ試行錯誤中ですが、チームの取り組みを紹介します。
Hermes - 開発早くするぞ!プロジェクト
これは、「どこに / どのぐらいのリソースを / どの期間 突っ込めるか」という課題に対して、まずは自分たちの戦闘力を知る必要があると感じました。 しかも定量的にです。なので、システムのメトリクスを取るように自分たちの開発力も可視化するようにしました。
個々の技術力の定量化は難しいとしても、チームの戦闘力はある程度可視化できるのではないかと思ったのがきっかけです。

いくつかメトリクスを取るレイヤーに分けています。 レイヤー1から順番に、ミクロ→マクロです。
- Layer 1. コードレベルでのチーム生産性の可視化 - pull request , commit , commentの量から生産性の健全性を可視化
- Layer 2. 開発フレームワークに合わせた、ストーリーポイントを元にした生産性の可視化 - Velocity, Cumulative flow, Control Chart
- Layer 3. 開発プロセス全般(MTGの間隔等々も加味した)のリードタイムの改善 - VSM(Value Streaming Mapping)

わかりやすい例で言えば、Layer 2の部分でPR(Pull Request)が出てからマージまでのタイミングを測定しています。 プロダクトを構成するリポジトリ(iOS, Android, Backend, Web Front)を分析しています。 それぞれチームも違うので、これによってリポジトリごとのPRの規模感やレビューの遅延などがわかります。目指す部分としては、この波が静かな方が生産性が安定していることなので、継続的にモニタリングすることによって自分たちの行動を振り返ることができます。

presented by @moriiimo
コードレビュー関連で言えば、もうひとつZenHubを使っての累積フロー(Cumulative flow)も有効です。
これは、Issueのレーン管理におけるパイプラインのメトリクスで、例えばSprintBacklog → Doing → Reviewというパイプラインを組んでいる場合のレーンの移動時間を集計してくれます。
これを累積フローに落とし込んで観察することで、DoingのIssueばかりが進んでいてレビューが滞っているという状態がわかったりします。そうするとDoingのWIP制限をかけて、レビューを皆で決まった時間に行い、チームとしての生産性を確保していこうという動きになったりします。 
Layer 3のVSMについては、こちらに詳しくあります。
このHermesプロジェクトは、まだ指標を探っている状態です。 きちんと運用に乗っけて、月イチでモニタリングをして、改善→モニタリング→評価→学習を繰り返していきます。
組織は「スループット」ではなく「レイテンシー」を上げる
開発速度という面でもうひとつ考えているのは、バッチサイズを小さくしてレイテンシーをあげるということです。
兎角、スモールチームでユーザーに適応しながらプロダクトをアップデートしていく構造であれば、 1つのバッチサイズを大きくせずにSingle Piece Flow(1つのサイクルで1つの仮説)を意識します。もちろんバッチサイズをひたすら小さくしてなんでもMVPでリリースすれば良いわけではありません。何を捨てて何を重要視するかを考え、レイテンシーをあげて必要がありますが、アジリティーをあげていくために意識していることです。

引用 : https://speakerdeck.com/i35_267/shi-ye-toenziniaringuwoxi-guli-xue
つまり、モノを運べる電車の大きさを大きくするのではなく、電車の速度を早くしようという感じです。

参考文献
7. 組織をエンジニアリングしないと、私たちは遠くに行けない
最後に組織のマネジメントについて述べていきます。 自分の中で、マネジメントは4つに分けています。上から順番に業務比重が多いですが、2つ目のHumanManagementについて考えたことを紹介できればと思います。
- ProductManagement(予算、事業戦略、KPI、データ分析、仮説立案)
- HumanManagement(組織設計、1on1、評価、育成、採用)
- ProjectManagement(アジャイル、リーン)
- Technology Management(アーキテクチャ、サーバーコスト、マイクロサービスとスモールチーム)
マネージャーは、確実に管理職ではない。マネジメントではなく"マネージ"する
この1年間で、色々とマネジメントの手法を考えている中でマネジメント = 管理のイメージがあることを懸念となっていました。 管理 = 悪のようなイメージもあり、エンジニアやデザイナーのロールモデルとしてあまり印象がよくないなと思いました。
しかし、マネイジメントは決して管理ではありません。管理しなくても自走する組織を作るのがマネージャーの仕事です。 もちろん、タックマンモデルのようなフェーズがあり混乱期などでは、意図してルールを作り、その中で行動を制約しながらチームを作っていくこともあります。ただし、それも監視するような管理ではなく構造を作っているだけです。
タックマンモデルとは、心理学者のTuckmanが「Tuckman’s stages of group development」という論文の中で提唱したモデルです。 チームというのは集まった瞬間からより良い成果を出せることは少なく、集団が相互作用しながら5つの過程を経ることで形成されていくとされています。メンバーが集まった段階では正しく機能せずに衝突する混乱を経て、きちんと機能する組織ができあがります。そのフェーズを避けるのではなく、一通り通過する必要があるとされています。

話を戻して、本来、「manage」という言葉は「何とかやり遂げる」「何とかする」という意味で、「管理する」の意味はありません。 つまり、マネージャーは組織に何か課題があったりしたときに、広い視野と視座で、何が何でも何とかする手段を考えて適応していきます。
そのためには、視座を高くして色々な知識を入れておかなければいけません。 視座をあげていくと、自然と自分に足りない知識が出てきます。詳しくは以下資料をご覧ください。
称賛文化の形成〜ピアボーナスの導入〜
「成功事例」効果ありだった取り組み事例
良いプロダクトを作るためには、組織のメンバーもモチベーションが高いことは大前提です。
アプローチは様々ですが、ピアボーナスは良い効果があると思っています。 ピアボーナスとは、仲間や同僚を意味する「peer」と報酬を意味する「bonus」を組み合わせた言葉で、従業員同士が日常の行動や貢献に対して報酬を与え合うしくみのことです。 給与や上長からの評価などと関係なく、チームメンバー同士での称賛文化を作りたい!というのが発端で、かれこれ3,4年、継続してやっています。
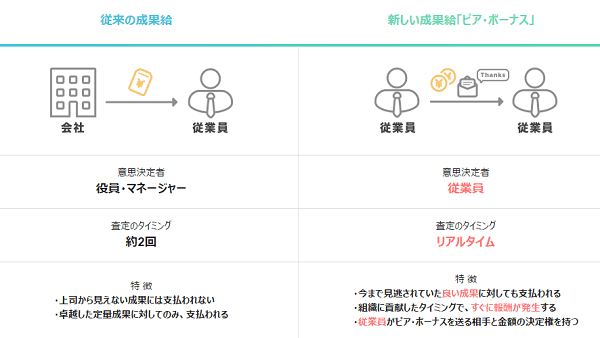
引用 : https://www.jnews.com/press/2017/0615.html
毎月1回ぐらい、チームリーダー層やメンバーからの投票によって選ばれたメンバーに対して、少しばかりの報酬とリーダー陣からのコメントがつけられて皆の前で表彰されます。

こういった、感謝を伝えるSlackチャンネルも大事です。意識的しなければ、思っていても伝わらないことが沢山あります。

presented by @kotokoto_fire
1on1を仕事の7割へ
現在、数的には、約50名前後のメンバーを管轄しておりますが、週に10~20人(MAX)x 30mぐらいをメンバーとの1on1を当てています。 権限委譲はしつつも、毎週やっているメンバーもいれば、月1のメンバーもいます。
プレイヤーからマネジメントになって、1番の変化は自分が生産性を出すのではなく、人を動かして生産性を出す点です。 メンバーのモチベーションに熱量を点火し、事業の方向性を定めて動かしていきます。
そこで1番大事なのは、対話です。つまり、1on1です。
個人的な1on1の方法論については、色々と試しているが、結局は型なので、個人で結構変えています。 medium.com
1番は、1on1でのモチベーションに熱量を点火することを心がけているので、明確に目標について会話したほうが良いメンバーもいますし、まったく仕事と関係ない会話をしたほうがリフレッシュになるメンバーもいます。そこは人によっても、同じ人でも日によっても違います。なので、あまり方法論に固執せずにやっています。
GRITを底上げする
もうひとつあるとすれば、GRIT(Guts / Resilience / Initiative / Tenacity)を上げることです。 GRIT(グリット)とは、和訳だと「やり抜く力」呼ばれているもので、何事も執念やとか、承認欲求とか、好奇心とか、執念とか、プライドとか、コンプレックスとか、そういう根底にある強い感情をフックにやり抜く力をつけることが大事だと言います。
どんなことが成果に繋がるかわからない世界の中で、将来の目標とか細かい目標設定とかキャリア論とかは、仮説でしかなく、暴論、なくても良い思っています。 ちょっとでも好奇心が向いたり、コンプレックスから執着心あるものに対して、レジリエンスを効かせながら、やり抜く力があれば、その先にきっといろいろなものが自然と見えてくるはずなので、各メンバーのGRITはどこなのかを見ています。
採用は最高の技術投資だが、最悪の技術投資にもなり得る〜採用はチーム全員でやる〜
よく採用は、マネージャーの仕事になりがちだが、チーム全員でやることが理想。 一次面接、二次面接等々は、マネージャー層でも良いが、最終的に近くで一緒に働くのは現場のチームメンバーです。なのでカジュアル面談でも良いので一度は採用前にメンバーとの会話から、今後も一緒に仕事ができそうかを客観的に見るようにしている。
人も技術投資と考えると、特に良いエンジニアの採用は、最高の技術投資になる。年収1000万のエンジニアを5人抱えると、ざっと年間5,000万の技術投資。 一方、事業を成り立たせるために必要な技術投資の中でも単純な技術投資と違って、人は不可逆性が高すぎる側面があります。このツール使いづらいから来月から契約終了しようといったことは、ツールはできても、人(特に正社員)だと難しい。
一番効果が高い技術投資だからこそ、採用は一番大事と言っても過言ではない。技術投資額(=年収)が高いから良い人そうとかそういう部分でもなく、きちんと今の事業や組織の課題を解決できる人なのか、いまのチームメンバーとの相性はきちんとあっているかなどを見る必要があります。 なんとなく凄そう人や業界で活躍している人だから、キャリアがすごいからとかだけで採用すると、組織文化にマッチせず、パフォーマンスを出せないためお互い不幸になります。 プロダクトを作るにあたって、一緒に作るメンバーの相性というのは非常に大事になってくる。特に少数精鋭で構成されたチームの中では1人でも価値観が合わない人を採用するとすぐに壊れやすくレジリエンスが効いた組織になりづらい。
権限と裁量をコントロールして組織のスケールさせる
組織が大きくなっていると、必ず権限委譲が必要になってきます。 意識していることは、「裁量」「責任」「権限」に一貫性をもたせることです。
責任はあるのに権限がないとか、裁量があっても責任と権限がないがあると、きちんとした権限委譲になりえずにレポートラインもぐちゃぐちゃになります。
また、きちんとその3つをコントロールしながら、必要に応じて「役職」を与えていきます。 これもまた、裁量と責任はあるけども、役職がないとなるとチーム外から見たときに、どのぐらいの決定権があるのかがわからなくなります。 小さい組織だけだった場合には、問題ありませんが、DMM規模の組織体になってくると必要な考えだなと思っています。
まとめ
- マネージャーは管理職ではなく、「何とかする人」
- そのためには、高い視座を意識して行動しなければいけない
- 自分の生産性ではなく、チームの生産性を意識する。1on1が主流へ
- 採用はチーム全員でやる
- 権限と裁量、責任のバランスを考える
全体まとめ
- 事業とエンジニアリングは、KPI x 仮説検証 x 技術で接続する
- スモールチーム(小さい集団 x n)で、レイテンシーを意識して戦う
- 組織をエンジニアリングする
以上です! 1年間の振返り記事でした。
からの記事と詳細 ( 事業をスケールさせるエンジニアリング〜技術のコモディティ化にエンジニアは敗北する〜 - DMM inside )
https://ift.tt/3EesHRC
0 Comments:
Post a Comment